Layers
You are probably sick of protocols by now but hopefully I can convince you that at least all of that effort was worth it. When you’re dealing with computer networks, there are some terms that you’ll see popping up quite often:
- IP
- TCP
- UDP
- DHCP
- HTTP
- FTP
- IMAP
- SMTP
Notice anything? They all end with the letter P! Well, all of those Ps stand for protocol! It’s a good thing you just spent a chapter becoming a protocol master. Now it is time to put these protocols to work.
In the previous chapter we saw an example of a concept that’s going to get a lot of use moving forward.
A layer is a protocol that allows for the transmission of arbitrary data.
For example, the protocols from the previous chapter could be described as layers since the data formats can contain any kind of data. The advantage of layers is that they allow us to split up the complicated task of communication into bite-sized pieces.
TCP
In the previous chapter, when we only needed to communicate between two computers, one protocol (one layer) was all that was needed. If a computer sent a packet, there was only one choice of recipient. Thus the protocol mostly concerned itself with matters like error checking, packet ordering, acknowledgement, etc.
The protocol we developed has a lot in common with the real-world Transmission Control Protocol (TCP). More generically, TCP is a protocol for packaging and transmitting information; but it is by no means the only such protocol. The User Datagram Protocol (UDP) performs a similar function. While TCP emphasizes reliability of the transmission, UDP emphasizes simplicity and speed.
If I’m overloading your brain, don’t worry. You can forget about these little details because—as I said—both of these protocols do basically the same thing.
The transport layer is the protocol that is in charge of packaging data for transmission.
To return to the analogy in the previous chapter, the transport layer tells you how to package your data and how the sender and receiver should handle those packages, but it doesn’t mention how those packages will actually get to their destination.
IP
Now comes the interesting bit. We’ve packaged our data in the transport layer, but how does it actually get where it needs to go? This is where the Internet layer comes in.
The Internet layer is the protocol that is in charge of getting data from its source to its destination.
As with the transport layer, there are multiple protocols that can be used in this layer. As far as we’re concerned, the eponymous Internet protocol (IP) is the only one that matters right now. The protocol itself is conceptually simple. In essence, it wraps the packet from the transport layer in an additional packet describing who is sending the data, and who the recipient should be. Then it simply sends it off to be delivered.
But who is it sending it to? How do they deliver it? To understand this we first need to make a little digression.
When you sign up for an Internet service with your cable company, what you’re really buying is the privilege of connecting your computer to a special kind of computer called a router. That’s it. It’s just as simple as in the previous chapter where we had two computers connected directly to each other. What’s special about a router is that it is designed to be connected to many computers at once.
All of the computers connected to a router are assigned addresses which identify them to the router—just like how the addresses of the homes in your neighborhood identify them to the local post office. These computer addresses have a very specific form.
An IP address is a 4 byte number identifying a computer on a network. By
convention, each byte is written in decimal with periods separating bytes e.g.
192.168.1.1 or 255.255.255.0.
This situation—many computers connected to a single router—is called a local network. The router (again, like a post office) acts as a mediator for messages between other computers. If two computers in the network wish to communicate, they don’t need to be directly connected, instead they can hand their messages off to the router and it will perform the exchange.
The situation starts becoming amazing when your router is connected to the router of a different local network. Now computers in both local networks can communicate. Imagine that you want to send a message to a computer in the other network. First you send the message to your router as usual, the router thinks “I’m not connected to that computer” so it sends it on to the other router. That router is connected to the other computer, so it can deliver the message. The beauty of this system is that each router only needs to know two things:
- The addresses of the computers connected to it
- The addresses of the other routers connected to it
Again, this system functions very similar to the postal service. Your local post office doesn’t know (or care) how to deliver a package to an address in another state: they simply forward the package to another post office that might know. This is the essence of the Internet—a network of interconnected routers all serving their own local networks and forwarding data to each other.
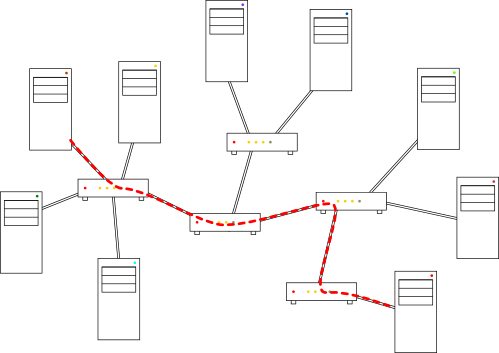
I say “essence” because of course the reality is much more complicated than that. To mention a few complications, there are hierarchies of routers established to ensure efficient routing of network packets, there are special provisions for the assignment of IP addresses, there are specialized routers in the network for handling certain types of messages, and there is the complicated matter of who owns all of these interlocking pieces.
Since an IP address has 4 bytes, that means that there are only 232 =
4,294,967,296 different IP addresses. Since every device connected to the
Internet needs an IP address, we’re actually running out of them. Because of
this we’re currently trying to transition to a new version of IP (version 6)
which has 128 bit addresses. IPv6 addresses are written in hexadecimal with
pairs of bytes separated by colons e.g. 2001:0db8:85a3:0042:1000:8a2e:0370:7334.
Now let’s poke around the Internet and see these principles in action.
For these exercises, we will be working in
a terminalthe command prompt—an
interface designed for running text-based programs on your computer.
To open it, press Win+R to open the Run dialog, type
cmd, and hit OK.
Depending on your computer, you might be able to open a terminal by pressing
Ctrl+Alt+T.
In Finder, you can find the terminal under Applications → Utilities.
The first program we’re going to use is called ping. It sends a
simple request to an IP address: ping me back. This is commonly used to test a
network connection. Type in the following and press Enter.
ping 127.0.0.1
Press Ctrl+C to stop the program.
Wow! We’re totally using the Internet! Well, actually I just played a bit of a trick on you. 127.0.0.1 is a special address: it is the IP version of “myself”. You’ve been sending your own computer messages! Now try it with a “real” IP. Here are some good ones:
192.168.1.174.125.228.242192.30.252.131
You can also try random IP addresses. For some of those you might get
no output
Request timed out.
and an ending summary showing 100% packet loss. This could mean several things:
there is no computer with that IP address, your computer couldn’t find a router
that delivers to that address, or the computer at that address is configured to
ignore pings.
DNS
Now we know that the Internet works using routers and IP addresses, but this picture still seems slightly different from the Internet that we know and love. There is one final piece to the puzzle.
Here is a link to the popular Google search engine: www.google.com. Now here is a link to an IP address (from the previous exercise): 74.125.228.242. Try opening both of them.
What is going on here? You might think that the second link was some kind of trick, when in fact the opposite is closer to the truth. The Google search engine is a program running on a computer somewhere. When you want to search for something with Google, you need to send Google information (your search query) and receive information in return (the search results). As we just learned, this is all done using the IP addresses of your home computer and the computer running the Google program.
But IP addresses are not very human-friendly. They are hard to remember and, what’s worse, they can change when the hardware of the computer or the infrastructure of the Internet changes. If Google wants to move their search engine to another computer (and thus a new IP) they definitely don’t want to have to notify all of their customers of the new IP address. Another likely scenario is that Google might have many computers running their search engine around the world. Connecting to a computer nearby is generally faster than connecting to one far away, so Google can offer a faster service by placing computers near their customers. But then customers would need to remember all of the different Google IP addresses based on their location.
The solution is the Domain Name System (DNS). The DNS acts like a kind of phone book for the Internet, associating human-readable domain names (www.google.com) with unmemorable IP addresses (74.125.228.242). Whenever your computer tries to send a message to a human readable name, your request first goes to a special computer called a name server which finds the right IP address. Then your request is sent through the network of routers to its actual destination. One of the things your Internet service provider gives you is the IP address of a name server to use.
Like the Internet itself, the DNS is incredibly complicated. The system of ownership, distribution, assignment, and maintenance of domain names is something that even I don’t understand.
One basic fact is that the DNS is hierarchical, with each domain being split
into subdomains administered by possibly different companies. You can see this
organization by reading the domain names from right to left. For example com
is a top-level domain with google.com and ebay.com as two of its subdomains.
In turn, maps.google.com and calendar.google.com are two subdomains of
google.com and so on.
You can investigate the DNS yourself by simply pinging domain names. If the DNS knows of the name, you will see the corresponding IP address in parentheses brackets. Give it a go:
ping google.com
If the domain name is invalid, you will get
an unknown host
a could not find host
message.
Now What?
The Internet layer gets your data where it needs to go and the transport layer makes sure that it arrives intact without errors, but what data are we actually sending? Well… anything.
The application layer is the protocol that actually communicates meaningful information.
In other words, the Internet layer and transport layer have done all of the menial work and all that’s left is the interesting stuff. Consequently, there are a huge number of protocols to choose from in the application layer. One reason for this is that standardization is far more important to the Internet and transport layers. Without those two layers, inter-computer communication would be essentially impossible; thus it is extremely important that every computer on the Internet agree on them.
However, once two computers do agree on those layers, agreeing on the application layer is less important. For example, as long the computers have one application protocol in common, they can use it to send each other information about other application protocols and thus expand their application layer repertoire.
We will discuss application protocols in greater detail in the next chapter.